MLST: Review on data sets for molecular ML potentials
Published Time: 2024-11-13 17:50:14
If you feel lost in the ocean of various datasets to train your machine learning potential, a comprehensive overview can serve as the compass to help navigate through the resources available.
Recently, we published a review on Machine Learning: Science and Technology exploring the current landscape of molecular quantum chemical data sets and databases. It covers key information on more than 40 datasets including the level of theory, size and diversity, methodologies, and availability.

For long-term and updatable maintenance, we established the GitHub repository to keep track of new datasets. Everyone is welcome to submit the pull requests on existing datasets we missed and the newly generated datasets.
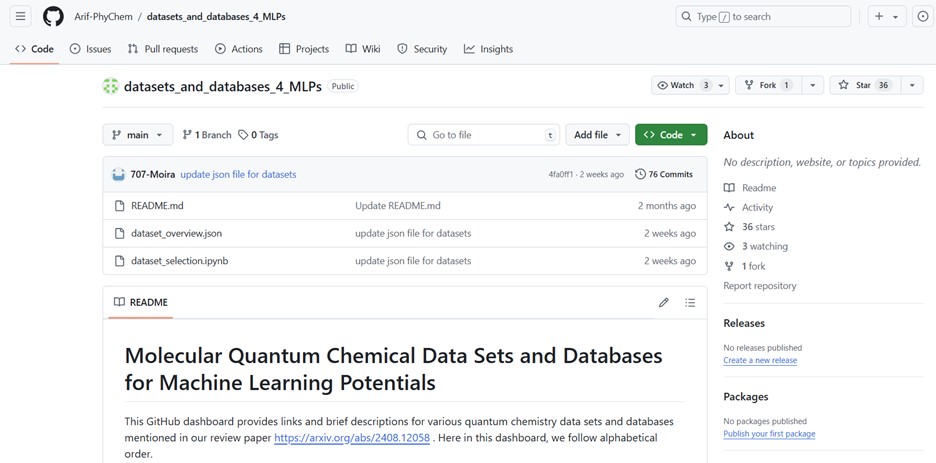
Alongside the paper, we also provide the lookup table in machine-readable format with the Jupyter Notebook example for analysis. It’s easy to find the datasets that suit your needs and generate the result sheet. No idea how to use heterogeneous datasets for training? Check our previous post on AIO (all-in-one) models that can train data on different fidelities.