5. Transfer learning
Transfer learning is a powerful approach complementary to delta-learning. Here you first train an ML model on more data obtained at the baseline QM method and then fine-tune (i.e., train only some/all parameters) on the fewer data at the target QM method. This can be also done, e.g., by training on the experimental data as a target. It is a powerful and easy to use approach and was also used in both AIQM1 and ANI-1ccx. In ANI-1ccx, the model was first trained on the 4.5 mln DFT data and then fine-tuned on 0.5 mln coupled-cluster data.
Below is a tutorial on TL from the MLatom’s documentation (prepared with Fuchun Ge). It is in Python – the full power of MLatom is on full display when using it as a Python library! It is not difficult though – we provide tutorial in the Jupyter notebook which is easy to use even without any knowledge about Python.
5.1. Slides
5.2. Jupyter notebook
You can upload it to the XACS cloud, launch Jupyter lab (click ‘Connect’ after launching), and open it in the Jupyter lab.
5.3. Tutorial
Transfer learning (TL) is an often-used technique in machine learning that helps you train better neural network models. The basic idea is to reuse the knowledge (parameters) of the pre-trained model from a different task, by fixing and changing some of its layers and then fit the model for a new task. There are serval reasons that we might utilize this technique:
Better training performance
The pre-trained models can give you a good starting point to kick off the training, which helps the convergence and might improve the accuracy of the final model.
Less data hungry
Training from a pre-trained model does not require data as much as training from scratch, since the pre-trained model already contains tons of information from its training data. This can be critical, especially when the accessibility to the data for the new task is limited.
Note that the advantages might not be able to be realized unless you choose your pre-trained model and train it properly. E.g. you definitely don’t want to use a totally unrelated model as the pre-trained model.
5.4. Transfer learning in MLatom
A typical transfer learning scheme includes:
Obtain the pre-trained model
Fix/change layers
Retrain
The first and last steps can be easily done in the normal MLatom routine (via model.__init__(model_file) and model.train()). While the second one might be a little bit complicated: we need to modify model.model.
Although platforms like PyTorch, Tensorflow have the flexibility to allow users to modify the model as they wish. This modification still requires a little bit deeper knowledge about the model’s architecture.
Fortunately, we provide some shortcut methods in our interface to TorchANI, to make it easier to fix some of the layers in a model (no quick methods for adding layers / other interfaces yet…).
Let’s see how it works.
5.5. ANI TL model
Here we just use hydrogen molecule as a simple example. The Jupyter notebook can be downloaded from the bottom of this page.
First we need to generate some data.
import mlatom as ml
import numpy as np
import matplotlib.pyplot as plt
# prepare H2 geometries with bond lengths ranging from 0.5 to 5.0 Å
xyz = np.zeros((451, 2, 3))
xyz[:, 1, 2] = np.arange(0.5, 5.01, 0.01)
z = np.ones((451, 2)).astype(int)
molDB = ml.molecular_database.from_numpy(coordinates=xyz, species=z)
# calculate HF energies
hf = ml.models.methods(method='HF/STO-3G', program='PySCF')
hf.predict(molecular_database=molDB, calculate_energy=True)
molDB.add_scalar_properties(molDB.get_properties('energy'), 'HF_energy') # save HF energy with a new name
# calculate CISD energies
cisd = ml.models.methods(method='CISD/cc-pVDZ', program='PySCF')
cisd.predict(molecular_database=molDB, calculate_energy=True)
molDB.add_scalar_properties(molDB.get_properties('energy'), 'CISD_energy')
Here we use HF/STO-3G and CISD/cc-pVDZ to generate two levels of energies for the geometry whose H-H bond lengths ranging from 0.5 to 5.0 Å.
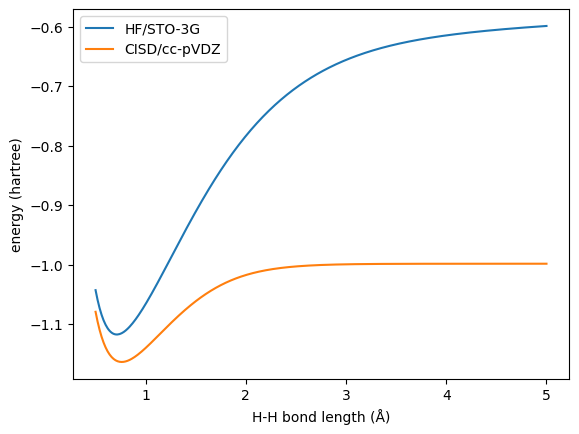
Then we can train an ANI model with HF energies to be the pre-trained model.
# train ANI model with HF energies
ani = ml.models.ani(model_file='ANI-HF.pt', verbose=False)
ani.train(molecular_database=molDB, property_to_learn='HF_energy')
# predict with trained ANI model
ani.predict(molecular_database=molDB, property_to_predict='ANI_HF_energy')
The model has a default structure as below:
Sequential(
(0): AEVComputer()
(1): ANIModel(
(H): Sequential(
(0): Linear(in_features=48, out_features=160, bias=True)
(1): CELU(alpha=0.1)
(2): Linear(in_features=160, out_features=128, bias=True)
(3): CELU(alpha=0.1)
(4): Linear(in_features=128, out_features=96, bias=True)
(5): CELU(alpha=0.1)
(6): Linear(in_features=96, out_features=1, bias=True)
)
)
)
Now let’s do transfer learning.
For this, you need to copy the file ANI-HF.pt with the model pre-trained on HF to ANI-HF-TL.pt file which will be used for fine-tuning on CISD.
# fix some of the layers
ani = ml.models.ani(model_file='ANI-HF-TL.pt', verbose=False)
ani.fix_layers([[0, 6]])
# transfer leaning with every 40th of the data
step = 40
val = molDB[::step][::10]
sub = ml.molecular_database([mol for mol in molDB[::step] if mol not in val])
ani.energy_shifter.self_energies = None # let the model recalculate the self atomic energies
ani.train(molecular_database=sub, validation_molecular_database=val, property_to_learn='CISD_energy', hyperparameters={'learning_rate': 0.0001}, reset_optimizer=True)
# predict with TL model
ani.predict(molecular_database=molDB, property_to_predict='ANI_TL_energy')
Here, we only use 12 CISD data points (subtrain/validate: 10/2) to train the TL model.
And we fixed the first and the last linear layer in the model with ani.fix_layers([[0, 6]]) (see mlatom.interfaces.torchani_interface.ani.fix_layers).
Also, we change the initial learning rate to a smaller value to make the training less aggressive.
Next, let’s train another model with the same data from scratch.
# train ANI model with CISD energies directly
ani_cisd = ml.models.ani(model_file='ANI_CISD.pt', verbose=False)
ani_cisd.train(molecular_database=sub, validation_molecular_database=val, property_to_learn='CISD_energy')
# predict with trained ANI model
ani_cisd.predict(molecular_database=molDB, property_to_predict='ANI_CISD_energy')
Now let’s check the results.
# plot the energies
plt.plot(xyz[:, 1, 2], molDB.get_properties('HF_energy'), label='HF/STO-3G')
plt.plot(xyz[:, 1, 2], molDB.get_properties('CISD_energy'), label='CISD/cc-pVDZ')
plt.plot(xyz[:, 1, 2], molDB.get_properties('ANI_HF_energy'), label='ANI-HF')
plt.plot(xyz[:, 1, 2], molDB.get_properties('ANI_TL_energy'), label='ANI-TL')
plt.plot(xyz[:, 1, 2], molDB.get_properties('ANI_CISD_energy'), label='ANI-CISD')
plt.plot(sub.xyz_coordinates[:, 1, 2], sub.get_properties('CISD_energy'), 'o', label='TL subtraining')
plt.plot(val.xyz_coordinates[:, 1, 2], val.get_properties('CISD_energy'), 'o', label='TL validation')
plt.legend()
plt.xlabel('H-H bond length (Å)')
plt.ylabel('energy (hartree)')
plt.show()
First, we can see that the ANI-HF model trained with all the data has excellent agreement with the reference.
While for the CISD level, the transfer learned model behave way better than the direct one.
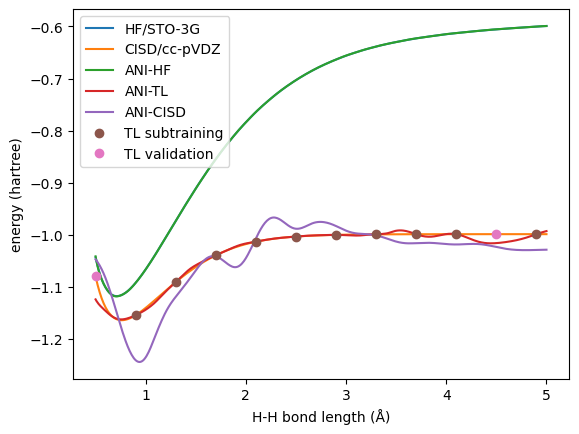
With this example, we can see the power of transfer learning: lower-level pre-trained model can boost the higher-level model even with a small training set.